Blazing fast search with MeiliSearch and Laravel Forge
As I am currently writing documentation for Invoker, I noticed something that was lacking on our Beyond Code website. All documentation pages were missing a search option. Now I could've chosen Algolia for this, or possibly even try and implement a fulltext search on MySQL myself. But instead I decided to go with MeiliSearch. A "Lightning Fast, Ultra Relevant, and Typo-Tolerant Search Engine". It also has support for Laravel Scout, which is pretty nice. Even though we're not going to use it on our own website.
Setting up MeiliSearch #
MeiliSearch itself is fully open-source and you can host and run your own search server. I decided to simply use one of our Laravel Forge provisioned servers for this. To install MeiliSearch, you can SSH onto your server and install the latest available version using this script:
# Install MeiliSearch latest version from the script
$ curl -L https://install.meilisearch.com | sh
To try out if everything worked, you can start the server by running ./meilisearch. You should see an output similar to this:
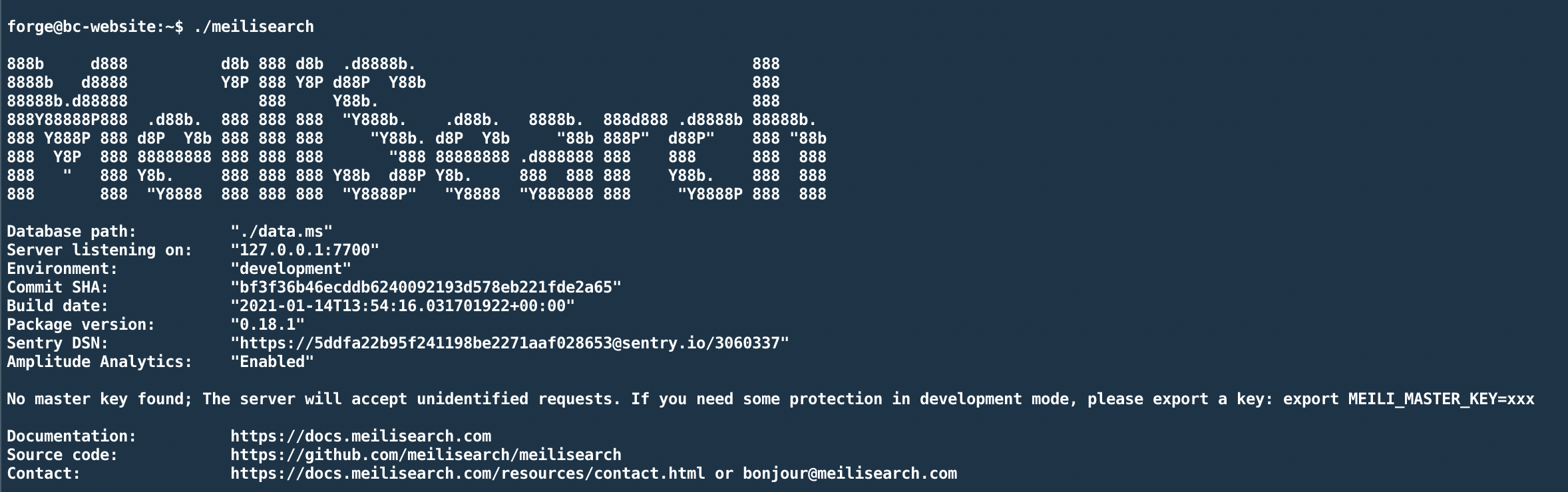
Alright, so our server is running on port 7700. But there's one important note here saying: "No master key found; The server will accept unidentified requests."
Uh oh, that does not sound like something we want. To run MeiliSearch in a production environment, and with a master key, modify the script like this:
./meilisearch \
--env production \
--http-addr 127.0.0.1:7700 \
--master-key YOUR-SECRET-MASTER-KEY
This will do a couple of things:
- Start MeiliSearch in production mode (this means that a master key is mandatory)
- We only accept HTTP requests coming from our own machine/network on port 7700
- We provide a very secret master key.
You can use any random string as the master key, just be sure to keep it secret. We will need this key later.
Accessing our server from the internet #
As mentioned above, we start the server and only allow access to it from the machine running the server instance itself. But in reality, we want to access the search server from the internet. Now we could of course expose port 7700 and access the search engine via HTTP - but we can do better than that.
Since all sites on Forge come with LetsEncrypt support out of the box, lets add a new site on our server that we will use as a reverse proxy for MeiliSearch.
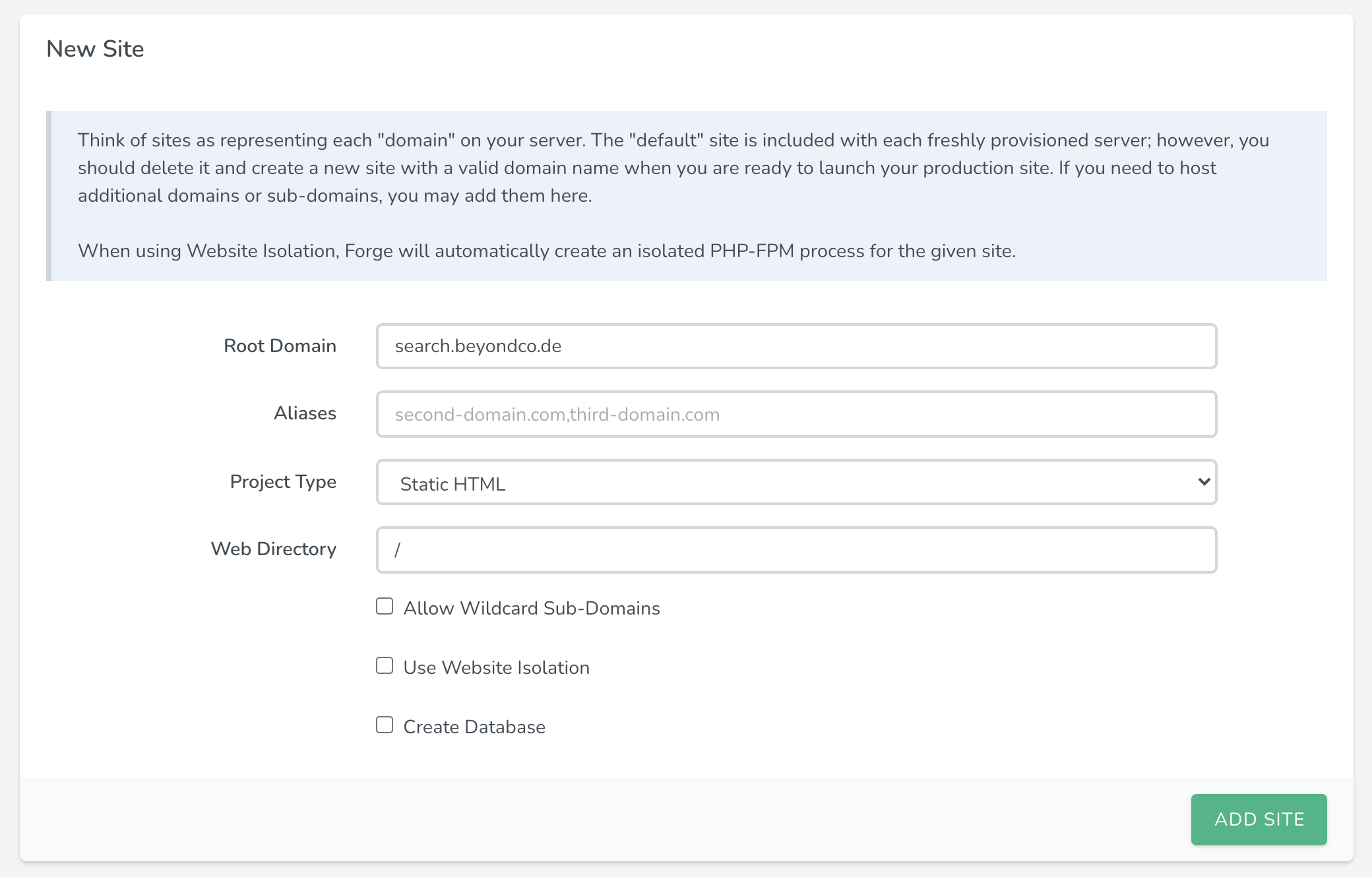
I simply added a new subdomain on one of our servers and chose "Static HTML" as the project type. Since we are not going to deploy any actual code on this site, it doesn't really matter. Next, be sure to point your subdomain's DNS entries to your Forge provisioned server.
After that is done, we can instruct Forge to obtain an LetsEncrypt certificate for us. The benefit is that Forge is going to take care of renewing our SSL certificate, whenever needed.
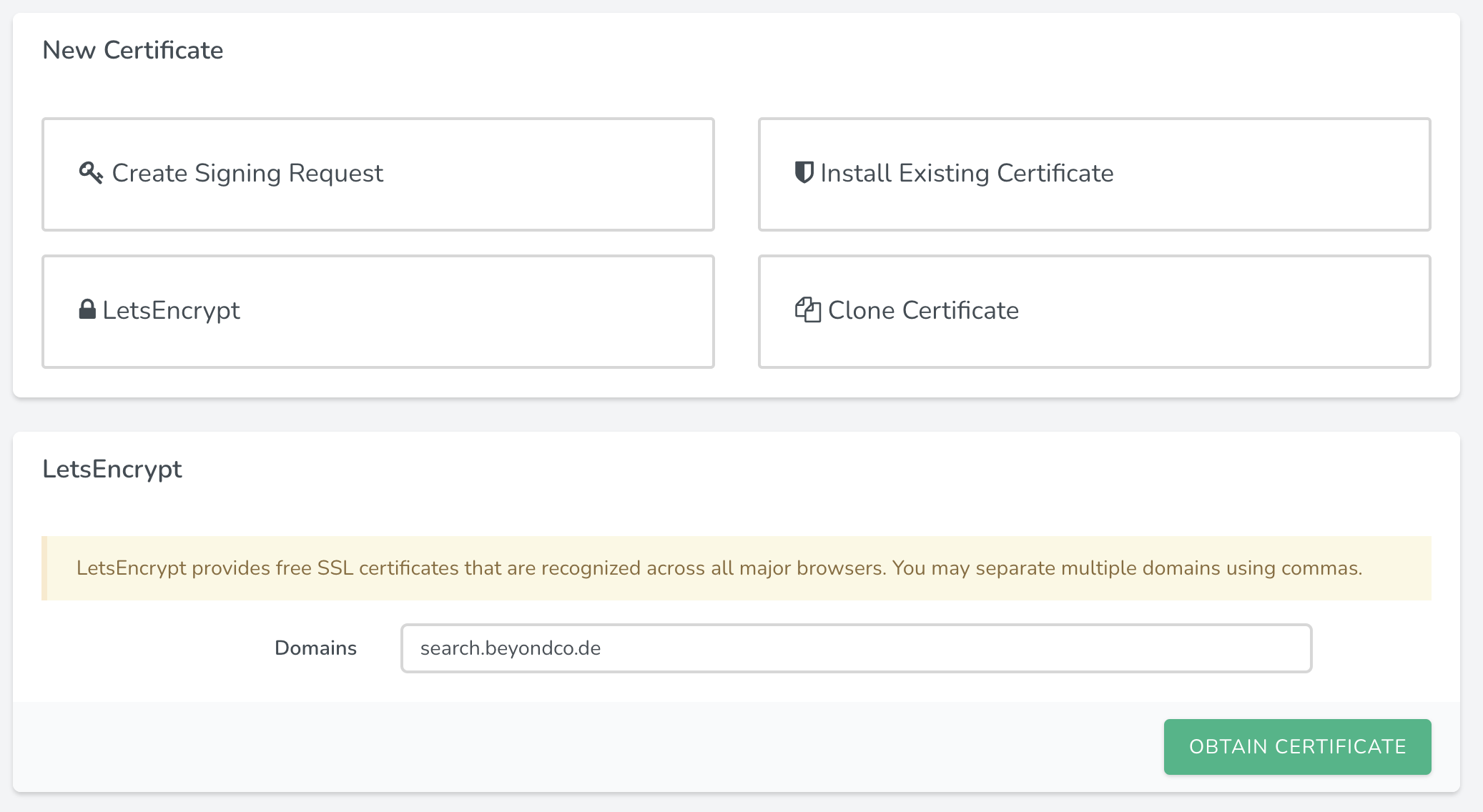
Alright, so now we have a subdomain with SSL - but it does not yet allow us to access our MeiliSearch server. Next, we are going to modify the Nginx configuration for this site and use it as a reverse proxy for our MeiliSearch instance.
Thankfully, this can all be done in the UI of Forge itself. You can do this by selecting "Files / Edit Nginx configuration"
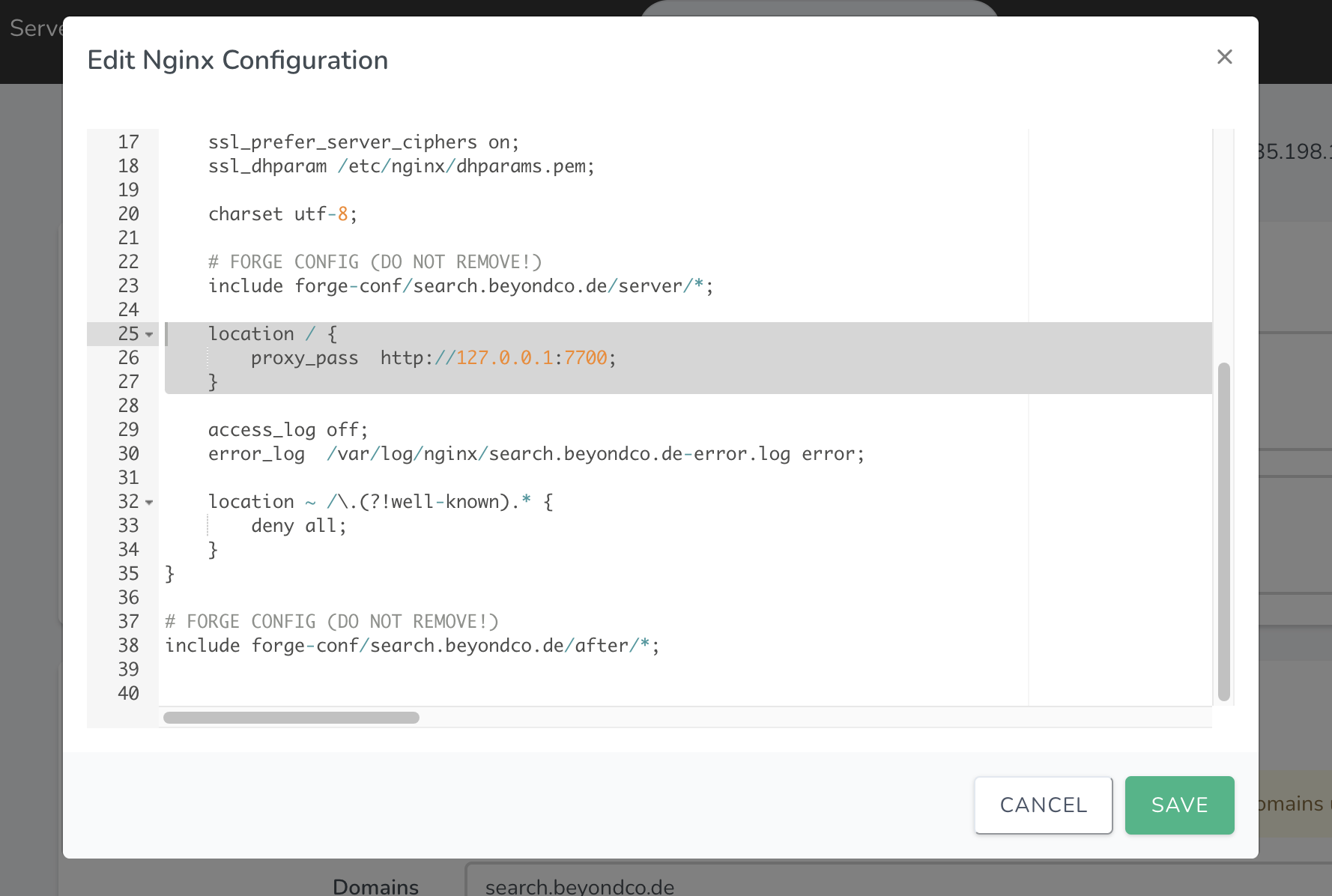
In here you should remove everything PHP related, as we do not want to host actual PHP files from our site. But instead we want to add this snippet:
location / {
proxy_pass http://127.0.0.1:7700;
}
This tells Nginx to pass all traffic to http://127.0.0.1:7700 - which is our MeiliSearch instance.
After you save the Nginx settings, you can ensure that you can access MeiliSearch on your site, by visiting https://your.subdomain.com/instances.
You should see a JSON response similar to this:
{
"message": "You must have an authorization token",
"errorCode": "missing_authorization_header",
"errorType": "authentication_error",
"errorLink": "https://docs.meilisearch.com/errors#missing_authorization_header"
}
Okay - so our server is accessible, but how can we add data to it/search it?
Retrieving our keys #
In order to either retrieve or store data in our search index, we need a private/public key combination, which we can retrieve using our master key. The one we set up when we started our search server, remember?
You can use something like Postman/Paw, or simply use curl to make this request and see the keys:
curl \
-H "X-Meili-API-Key: 123"
-X GET 'https://your.subdomain.com/keys'
The response should be something like this:
{
"private": "8c222193c4dff5a19689d637416820bc623375f2ad4c31a2e3a76e8f4c70440d",
"public": "948413b6667024a0704c2023916c21eaf0a13485a586c43e4d2df520852a4fb8"
}
Adding the documentation #
From this point on, you are able to use your MeiliSearch server with the official Laravel Scout driver. In my case, I want to add the content of our documentation sites to MeiliSearch. The content is already online and gets generated from various markdown files. So I could either build some kind of markdown parser myself and then pass the parsed data to MeiliSearch - or use the awesome docs-scraper from MeiliSearch.
This is a python script, that allows you to do just that - it scrapes your documentation websites and you provide it a configuration file with the start/stop URLs or a sitemap , as well as some CSS selectors for the different heading levels and texts.
This gets written to a config.json file. In the case of our Beyond Code documentation, it looks like this:
{
"index_uid": "docs_websockets",
"selectors_exclude": ["a.ml-2.text-hulk-50.font-sans"],
"start_urls": ["https://beyondco.de/docs/laravel-websockets/"],
"stop_urls": [],
"selectors": {
"lvl0": {
"selector": ".menu.hidden ul:nth-child(1) > li.active > a",
"global": true
},
"lvl1": {
"selector": ".markdown h1",
"global": true
},
"lvl2": ".markdown h2",
"lvl3": ".markdown h3",
"lvl4": ".markdown h4",
"lvl5": ".markdown h5",
"lvl6": ".markdown h6",
"text": ".markdown"
}
}
Now when we run the docs scraper, it creates a new index called "docs_websockets" and parses the HTML from https://beyondco.de/docs/laravel-websockets/ and follows all of its links within the same root URL.
For me, the easiest way to actually run the scraper was using Docker:
docker run -t --rm \
-e MEILISEARCH_HOST_URL=https://your.subdomain.com \
-e MEILISEARCH_API_KEY=your-private-key \
-v ABSOLUTE-PATH-TO-YOUR/config.json:/docs-scraper/config.json \
getmeili/docs-scraper:latest pipenv run ./docs_scraper config.json
This is a test search result after the first scraping:
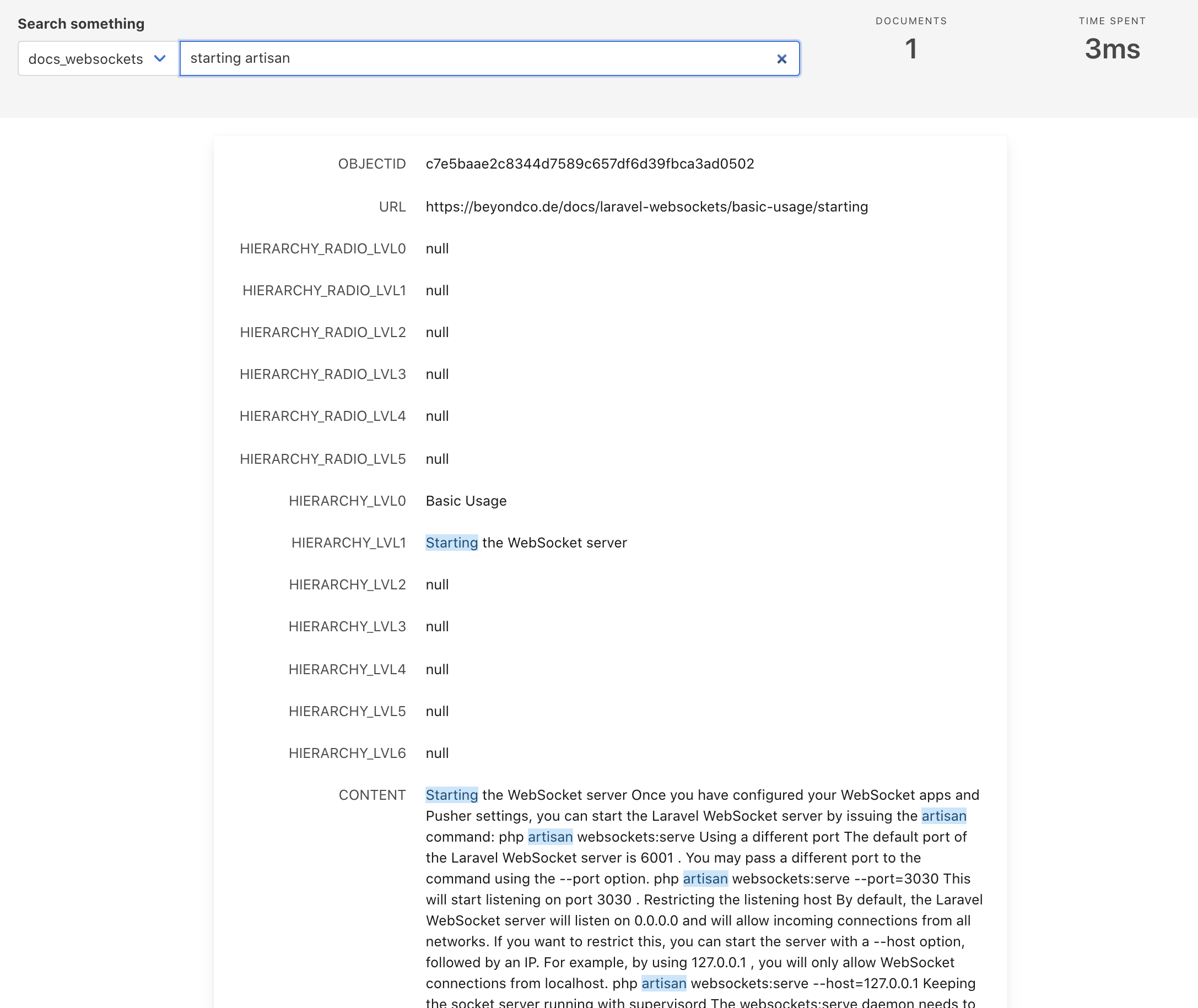
Adding the frontend #
This basically was the required backend part of our search server. Now that the documentation is scraped, we can add a frontend component to show the search results as we type.
Luckily, MeiliSearch offers something out-of-the-box as well: docs-searchbar.js.
Here's a very simple implementation of the searchbar:
<!DOCTYPE html>
<html>
<head>
<link
rel="stylesheet"
href="https://cdn.jsdelivr.net/npm/docs-searchbar.js/dist/cdn/docs-searchbar.min.css"
/>
</head>
<body>
Search:
<input type="search" id="search-bar-input" />
<script src="https://cdn.jsdelivr.net/npm/docs-searchbar.js/dist/cdn/docs-searchbar.min.js"></script>
<script>
docsSearchBar({
hostUrl: "https://your.subdomain.com",
apiKey: "YOUR-PUBLIC-KEY",
indexUid: "YOUR-SEARCH-INDEX",
inputSelector: "#search-bar-input",
debug: true, // Set debug to true if you want to inspect the dropdown
});
</script>
</body>
</html>
And that's about it. Now we have our own search server up and running behind an Nginx reverse proxy - and our own frontend solution to search and query it. If you want to customize the look and feel of it, check out the customization section of docs-searchbar.js.
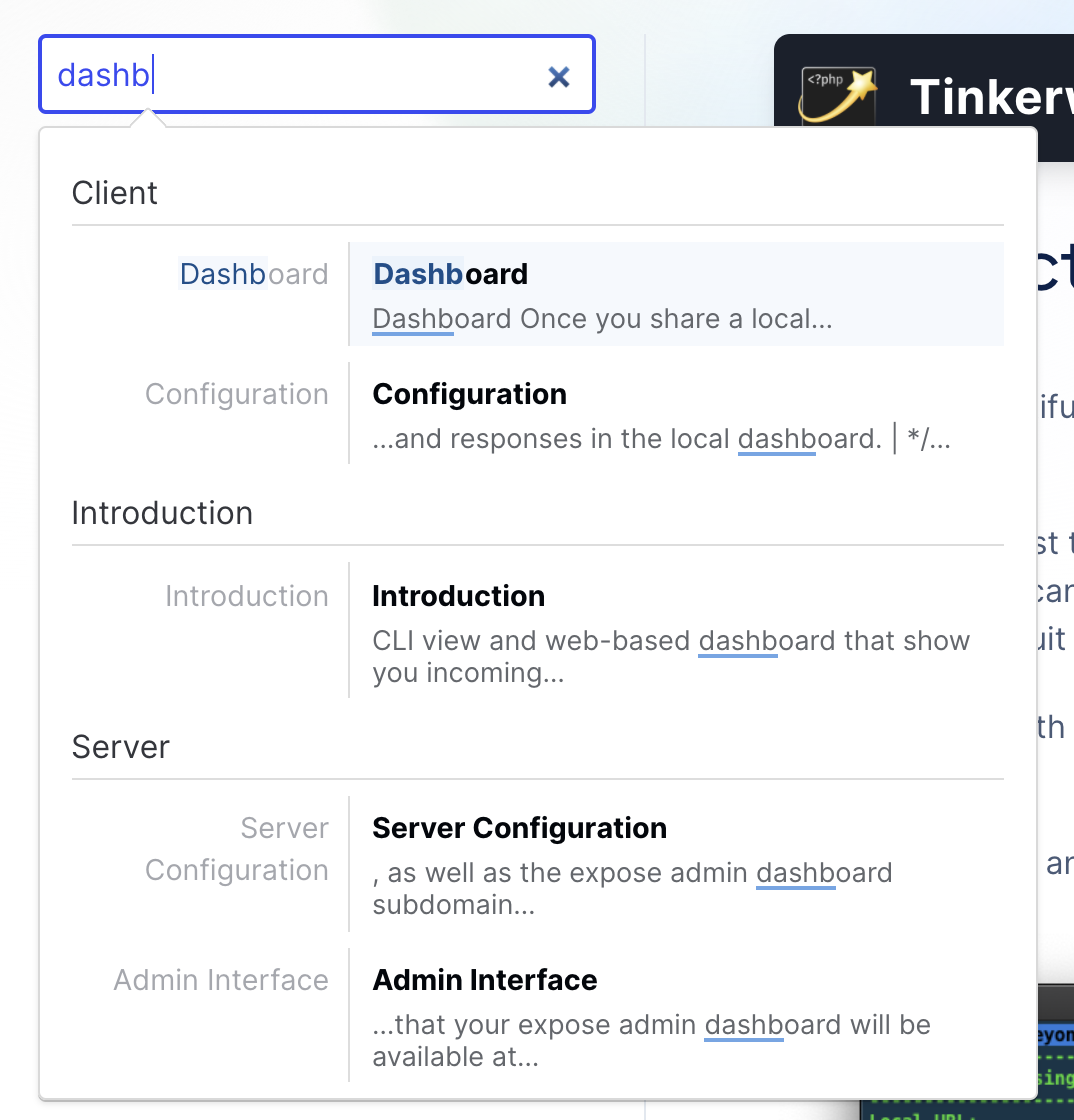
You can see the new documentation search in action on our website.